
Configuring a File Loading Data Pipeline with transformation
Before configuring a Data Pipeline with transformation, the following steps should be completed:
Provision a Data ETL service (App Connect)
Engage IBM Integration services (through Expert Labs) to build an App Connect flow to perform the file transformation
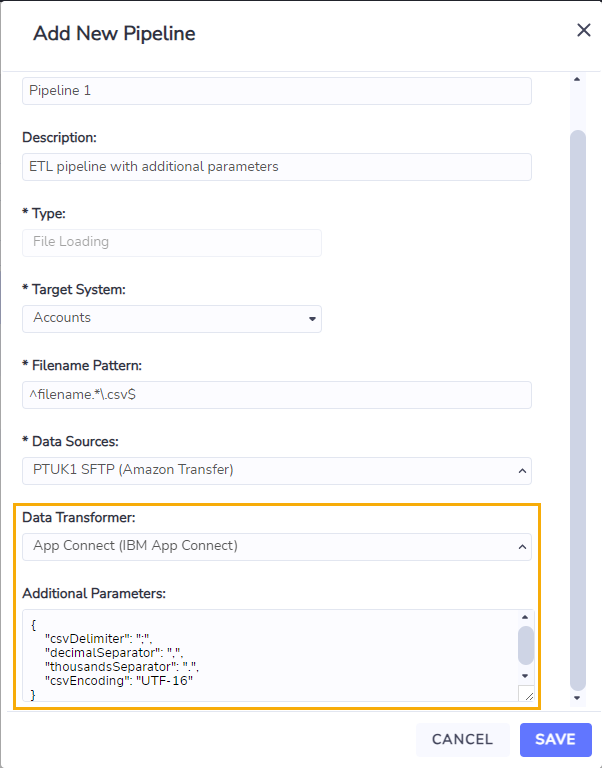
The process for configuring a Data Pipeline with transformation is similar to Configuring a Data Pipeline without transformation. The only additional steps required are:
In the Data Transformer field - select the Data ETL service instead of None.
Optionally, use the Additional Parameters field to set the following parameters for file processing (refer to the panel below for further information):
csvDelimiter
decimalSeparator
thousandsSeparator
csvEncoding
Additional Parameters can be used to process files which do not match the default values below. Note that these parameters are currently only enabled for Data Pipelines using an App Connect transformation.
If the additional parameters field is blank, the following default values will be used.
“csvDelimiter”: “,”
“decimalSeparator”: “.”
“thousandsSeparator”: “,”
“csvEncoding”: “UTF-8”
The format of the additional parameters field must be a valid JSON string as shown in the screenshot above.